Chapter 5: Quantitative Methods Used In Human Resources
STATISTICAL TESTS AND INFERENCE
Statistical Tests
A statistical test allows you to deduce the reality from a limited amount of data. There are two basic types of tests:
-
Parametric utilizesassumptions that a sample's observations are:
- random
- independent
- normally distributed
- Non-parametric utilizes no assumptions when the parameters are not know.
Graphically, statistical tests can be illustrated as shown below:
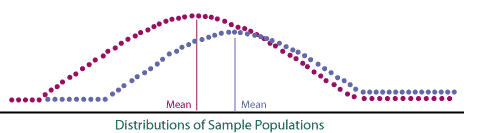
Both parametric and non-parametric tests rely upon the basic underlying concept:
Are means and distributions similar?
If the means and distributions are not similar, a difference between the two samples can be statistically proven.
Would you expect a salary survey to be normally distributed?
Statistical tests solution
No, there are always underlying minimums (minimum wage, not paying positions below those they supervise, etc. Also high salaries that are anomalies).
Hypothesis
Parametric and non-parametric tests examine a hypothesis. Confusing to many, statisticians test propositions to disprove what they wish to prove. They state that no difference exists; this is the null hypothesis, and this is what is tested.
Null hypothesis example
For each instance below, state the null hypothesis:
- Is a sample random?
- Do selection techniques favor males?
- Do men perform better than women?
- Is a benefits communication program effective in raising employees' awareness of the importance of preventative maintenance?
- Are promotional opportunities different for protected and non-protected groups?
Null hypothesis solution
- The sample occurs in a random order.
- There is no gender bias in the selection techniques.
- There is no correlation between gender and performance.
- The benefits communication program was not a factor in raising employees' awareness of the importance of preventative maintenance.
- Promotional opportunities are the same for protected and non-protected groups.
The notation for a null hypothesis is H0.
Inference
The field of statistics is quite different from the common idea we receive through newspapers and other media. In the media, the statistician is represented as a person who collects great amounts of quantitative data, and then abstracts significant numbers from that information. We are all familiar with the notion that the determination of average salaries in an industry or the average number of children in urban American families is the statisticians' job, but one who has taken even an introductory course in statistics knows those examples are pieces of a much larger field.
A central topic of modern statistics in human resource administration is that of statistical inference. This is concerned with two types of problems: 1) estimation of population parameters and 2) tests of hypotheses. It is with the latter, tests of hypotheses, that we will concern ourselves.
Webster's Dictionary tells us that "to infer" means "to derive as a consequence, conclusion or probability." A woman wears no ring on the third finger of her left hand, so we infer that she is unmarried. A man wears no ring, and we infer nothing (cultural assumptions that may be disappearing).
In statistical inference, we are concerned with how to draw conclusions about a large number of events on the basis of observations of only a portion of them. Statistics provides the tools that formalize and standardize our procedures for drawing conclusions. For example, if we wish to determine which of three stock option plans is most popular in U.S. companies, we gather information; if we gathered all the information on every U.S. company, we would never finish. So we consider collecting a sample.
The procedure of statistical inference introduces order into our attempt to draw conclusions from evidence provided by samples. The logic of the procedure dictates some of the conditions under which the evidence may be collected, and statistical tests determine how large the observed differences must be before we can have confidence that they represent real differences in the larger group from which only a few events have been sampled.
A common problem for statistical inference is to determine, in terms of probability, whether observed differences between two samples signify that the two populations sampled are themselves different. We will examine two methods of deciding this: parametric and non-parametric tests.
The table below is provided to assist with the application of various tests in the following case studies:
| Test | Type of Data Required | Type of Test | ||
|---|---|---|---|---|
| Nominal | Ordinal | Interval | ||
| Binomial Test | x | x | x | Non-parametric |
| Kilmogorov-Smirnov Test | x | x | Non-parametric | |
| Chi-Square Test | x | x | x | Non-parametric |
| Runs Test | x | x | Non-parametric | |
| McNemar Test | x | x | x | Non-parametric |
| Sign Test | x | x | Non-parametric | |
| Z Test | x | Parametric | ||
| Student's t Test | x | Parametric | ||
| Fisher Exact Probability Test | x | x | x | Non-parametric |
| Median Test | x | x | Non-parametric | |
| Mann Whitney U Test | x | x | Non-parametric | |
| Wald-Wolfowitz Runs Test | x | x | Non-parametric | |
Z Test
The most commonly illustrated statistical test is that in which a sample is compared to known population parameters to test if the sample has come from that population. Described as the estimation of sigma (S), we will call this the Z test.
We will provide no practical example for the Z test because although it is one of the two parametric approaches available, its requirements are such that the standard deviation must be known as well as the mean of the population. We question the Z test applicability in general human resource administration, and because of this, we will introduce various other tests that will serve as substitutes.
The equation for the test is:
Z = X - Assumed Mean Standard Deviation
Z test example
Suppose one had the following interval: independent and random measurements drawn from a normally distributed population with a standard deviation of 6.7 and a mean of 55.
| 119 | 30 | 33 | 30 |
| 95 | 112 | 11 | 30 |
| 72 | 90 | 12 | 35 |
| 51 | 93 | 26 | 34 |
| 48 | 64 | 28 | 87 |
If we estimate that the mean for the sample is 60, would this be reasonable? (Assume a confidence level of 95%.)
Z test solution
The null hypothesis would be that both means come from the same population. Since we know the standard deviation, we can utilize the Z test.
Z = X - Assumed Mean Standard Deviation
| Z = |
55 - 60 6.7 |
Z = -0.746
Inspecting the probability for Z = 0.746 in the Z Table, we find 0.2278. This suggests that roughly 2 out of 10 times, we can expect to find the mean value of 60 from this sample. Hence, we cannot reject the null hypothesis.
Student's t Test
The concept that one can test partial results for confidence in such results, whether the results match a certain defined population, has already been covered. However, we almost never know the standard deviation of the population. More often than not, we are testing two samples, one against the other, to see whether they have come from the same population.
When using interval data for normally distributed populations, we can use the Student's t Test.
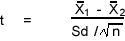
Here X is the mean of one sample, and X2 is the mean of the other sample. We need to solve for the standard deviation rather than having it given as in the Z test example above.
Student's t test example
Suppose you are supplied with a survey of salaries for 200 companies compiled and documented by a search firm. You wish to know if one can confidently use the information. To check, you call 4 of the 200 companies and compile information as to the average salary for 10 positions. The data appears as follows:
| Position | Search Firm's Data ($)* | Your Data ($)* |
|---|---|---|
| d1 | 49,000 | 47,000 |
| d2 | 32,000 | 31,000 |
| d3 | 28,000 | 30,000 |
| d4 | 29,000 | 26,000 |
| d5 | 29,000 | 24,000 |
| d6 | 33,000 | 31,000 |
| d7 | 22,000 | 21,000 |
| d8 | 19,000 | 20,000 |
| d9 | 19,000 | 18,000 |
| d10 | 18,000 | 16,000 |
Write out the null hypothesis for this data, and then test the hypothesis. Assume a confidence level of 95%.
Student's t test solution
The null hypothesis is:
H0 = XA - XB = 0
Now solve for the Standard Deviation (Sd):
| Position | Search Firm's Data ($) | Your Data ($) | Difference (d) | d2 |
|---|---|---|---|---|
| d1 | 49,000 | 47,000 | 2,000 | 4,000,000 |
| d2 | 32,000 | 31,000 | 1,000 | 1,000,000 |
| d3 | 28,000 | 30,000 | 2,000 | 4,000,000 |
| d4 | 29,000 | 26,000 | 3,000 | 9,000,000 |
| d5 | 29,000 | 24,000 | 5,000 | 25,000,000 |
| d6 | 33,000 | 31,000 | 2,000 | 4,000,000 |
| d7 | 22,000 | 21,000 | 1,000 | 1,000,000 |
| d8 | 19,000 | 20,000 | 1,000 | 1,000,000 |
| d9 | 19,000 | 18,000 | 1,000 | 1,000,000 |
| d10 | 18,000 | 16,000 | 2,000 | 4,000,000 |
| Sum | 278,000 | 264,000 | 20,000 | 54,000,000 |
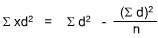
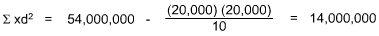
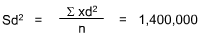
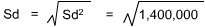
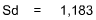
Solving for t:
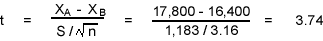
From Table 3, the probability of t = 3.74 at 9 degrees of freedom (e.g. total number of possible outcomes minus 1 - in this example, 10 - 1 = 9 degrees of freedom) is much greater than the 5% significance level given. Therefore, we reject the null hypothesis. The results for the search firm's data differ significantly from your data.
Testing for Confidence: The Binomial Test
Many times, assumptions inherent in parametric tests cannot be accepted. When this occurs, nonparametric tests can be applied.
For example, a company has a sales force comprised of one half women and one half men. Each fall, discretionary trips are given to 18 sales personnel for "loyalty," "creativity" and "company spirit." The past awards were given to 12 men and 6 women. You wish to be right 9 out of 10 times (hence, a 0.1 confidence level). Could you say that gender statistically has something to do with how the awards were allotted?
The null hypothesis is:
H0 = M - F = 0 (no gender bias exists)
Binomial test chart
Table 4 illustrates probabilities given N and x. The table below is a summary of probabilities when N = 18 and x ranges from 2 to 8:
| > N | > x | > Probability |
|---|---|---|
| >18 | 2 | 0.001 |
| 18 | 3 | 0.004 |
| 18 | 4 | 0.015 |
| 18 | 5 | 0.048 |
| 18 | 6 | 0.119 |
| 18 | 7 | 0.240 |
| 18 | 8 | 0.407 |
The formula for calculating this probability is:
| p(x) = (N / X) PXQN - X | |
| where (N / X) = |
N! X! (N - X)! |
Remember: In mathematics, "!" is the symbol for the operation of multiplying an integer by all the positive integers less than itself; this is called the factorial symbol: e.g., 3! is 3 x 2 x 1. A Factorial Table is available in the Appendix of this textbook.
| p(x) = |
18! 12! (18 -12)! |
(1/2)12 (1/2)(18-12) |
| p(x) = |
6402373705728000 479001600 x 720 |
0.00024414 x 0.01562500 |
| p(x) = | 18,564 x 0.0000038146875 | |
| p(x) = | 0.0708 or 7% | |
The probability of exactly 12 men and 6 women being awarded the trips is 7%. Our null hypothesis states that gender does not have anything to do with the awards. A 7% probability that 12 men and 6 women will be awarded the trips is a pretty low number and implies that the chances are low that men will outnumber women by two times in getting awarded a trip. Therefore, you have reason to reject the null hypothesis and conclude that gender bias may have played a role in how these trips were awarded.
Binomial test example
You are selecting from a population made up equally of Mexicans, Canadians, Japanese, Chinese, Algerians and Brazilians. What is the probability you will choose 2 Chinese out of 5 selected employees?
Binomial test solution
| p(2) = |
5! 2! (5 - 2)! |
(1/6)2 (5/6) (5 - 2) |
| p(2) = |
120 2 x 6 |
0.0278 x 0.5787 |
| p(2) = | 10 x 0.0161 | |
| p(2) = | 0.161 or 16% | |
You find that 16% of the time, one would expect two of any nationality from this population of 5 employees to be selected.
Chi-Square Test (one sample)
The chi-square (X2) one-sample test lets you examine whether the number of scores recorded falls into expected categories. The X2 test is excellent for use in opinion surveys, especially those that use a two or three part answer format. It also allows you to examine results to analyze the degree of "chance" that may have entered into a measurement.
The equation for calculating X2 is:

This is a quantifiable measurement to be compared to the Chi-Square Table (found in the appendix of this text.)
Chi-square example
A benefit administrator takes a random survey of 100 employees, asking each if they would prefer that the organization spend extra dollars on improved:
- life insurance
- medical benefits
- disability benefits
- salaries
He explains that only one of the four alternatives can be afforded. The survey results are:
| Selected By | |
|---|---|
| Improved Life Insurance | 12 |
| Improved Medical Insurance | 31 |
| Improved Disability Insurance | 18 |
| Added to Salaries | 39 |
Is a statistical difference apparent?
Chi-square solution
The null hypothesis is that no difference is expected among the four categories. Any observed differences could be assigned to chance found in a random sample. Since we are comparing measurements from one sample to an equally distributed population (although this is not necessary), and because the measurements are nominal, the chi-square (X2) test is in order. Let us choose a level of confidence of 99% (i.e., a = 0.01) and N = 100. Also, degrees of freedom (df) need to be defined. That is: "Cases - 1," and in this example, four different responses are possible; hence the degree of freedom is 3, (4 - 1 = 3).
Drawing this out, we have:
| Item Number | 1 | 2 | 3 | 4 |
| Expected Response | 25 | 25 | 25 | 25 |
| Actual Response | 12 | 31 | 18 | 39 |
The X2 would be:
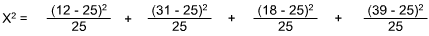
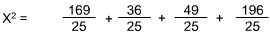
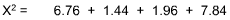
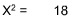
Using the Chi-Square Table, the value of 18 is greater than that shown for a = 0.01 at df =3. Hence, one could reject the null hypothesis. Some non-random difference in preference exists.
Kolmogorov-Smirnov Test
The Kolmogorov-Smirnov Test is a test of the fitting of an expected distribution to that of an actual set of measurements. It describes what one can expect measurements to have been when drawn from a theoretical distribution. It works well with ordinal data.
The test is appropriate for cases where cumulative expected frequencies can be calculated. These frequencies are compared to actual cumulative frequencies, and for each group, the difference between the two is calculated. The difference that is the largest is termed the maximum, and this maximum is compared to the Critical Value Table. If the computed value is greater than that shown for the selected level 'of confidence, the null hypothesis can be rejected and the assumption proved.
Kolmogorov-Smirnov test example
The human resource clerk keeps track of the years of college education that job candidates have. She divides the groups into four categories, into which the group is equally divided and compares these to the offers extended. Her findings are:
| Years of College |
Number of Candidates |
|---|---|
| 1 | 0 |
| 2 | 1 |
| 3 | 4 |
| 4 | 7 |
What conclusions can be made?
Kolmogorov-Smirnov test solution
The null hypothesis is: There can be no difference expected among the groups. Any observed difference should be explained by chance.
The Kolmogorov-Smirnov test would be used because the data is ordered and one is testing a distribution. Because of the nature of this test, let us choose a high level of confidence: a = 0.01.
Years of College |
||||
| Number of candidates offered a position | 0 | 1 | 4 | 7 |
|---|---|---|---|---|
| Expected distribution | 3/12 | 3/12 | 3/12 | 3/12 |
| Cumulative distribution expected | 3/12 | 6/12 | 9/12 | 12/12 |
| Cumulative distribution in actuality | 0/12 | 1/12 | 5/12 | 12/12 |
| Difference | 3/12 | 5/12 | 4/12 | 0/12 |
Using the Kolmogorov-Smirnov Table, the ratio 5/12 = 0.417 is not greater than the 0.450 required. Hence, one could not conclude any significance of these measurements with a confidence level of 0.01. If one wishes to use a 95% measure of confidence, however (a = 0.05), one could reject the null hypothesis and draw the conclusion that years of college education was highly correlated to job offers.
Runs Test (a test on the bias of a sample)
The Runs Test allows an observer to draw conclusions about a set of data presented or available for analysis. It is an examination of the order of sequence, and is a test of frequency rather than results.
Two measurements are made in conducting this test. The first, N1, is the number of one of two items found; the second, N2, is the number of the second. The total population N should equal N1 + N 2. The test is a simple observation of the distribution, counting the runs. One then compares the results to the Runs Table.
Runs test example
Suppose that an EEO auditor suspects the "doctoring of statistics" in the frequency counts of minorities versus majority groups passing an entrance test. The suspicion has arisen because of the observation that the majority group (50% of the population could be accepted) had a pass/fail distribution over a year period that was:
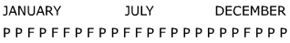
It appears that the frequency of passes was increased later in the year; what can be concluded?
Runs test solution
The null hypothesis would be that the Passes and Fails occur in a random order.
This randomness test concerns a single set of occurrences that can be measured as Yes / No or, + / -. Pass is equal to "+." Fail is equal to "-." Let the confidence level be 95%, a = 0.05.
Counting the runs:
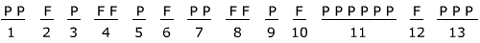
Using the Runs Table and N1 of 16 and N2 of 8, the run total of 13 is much higher than the limit of 6. We could not reject the null hypothesis.
McNemar Test for Change
The McNemar Test is for significance of change. Applicable to tests for before-and-after changes, it is particularly applicable to testing and training. Ordinal and nominal data can be used; in such cases, the people themselves serve as the control points. As such, it works well with related samples (i.e., independence is not required).
The test can be illustrated in a box matrix form:
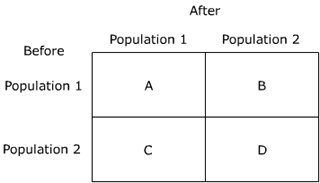
The test equation represents actual measurements:
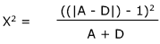
| | is the symbol for absolute value. The number must be positive.
The significance of this test is found by comparing X2 to the Chi-Square Table. If it is equal to or greater than the number shown for (usually) one half the probability chosen (e.g., 20 should use 0.10, because the test is for change in only one direction) it is significant.
McNemar test for change example
A management staff has shown an inadvertent prejudice against African-Americans, Asians and minorities who comprise 50% of the sales staff. At sales meetings, an assistant to the president notes that conversation initiated by corporate officers almost always is directed towards white male salesmen. The president believes this is a symptom of a greater problem and has embarked on a complete team building interaction program. The assistant is asked to again view conversations initiated by the 30 members of the corporate staff after the training and finds that of 20 corporate staff members at the next sales meeting:
- 10 officers changed and now initiated their first conversation toward a female or other minority rather than a Caucasian male
- 6 officers remained unchanged
- 3 officers who had originally initiated their conversations toward minorities now initiated their conversations toward Caucasian males
- 1 officer who had originally initiated her conversation toward minorities remained unchanged
Has a significant change been shown to occur?
McNemar test for change solution
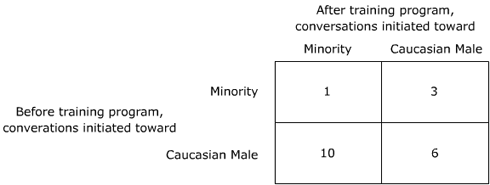
- 10 officers first went to Caucasian males, but then changed, so they are placed in box C
- 6 officers first went to Caucasian males and didn’t change, so they are placed in box D
- 3 officers first went toward minorities, but changed to Caucasian males, so they are placed in box B
- 1 officer first went to a minority and didn’t change, so 1 is placed in box A
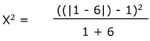
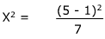

Now that you have X2, use the Chi-Square Table in the Appendix. The degree of freedom used is found by taking the number of rows minus 1, and multiplying this by the number of columns minus 1. (2 - 1)(2 - 1) = 1.
The calculated X2 of 2.29 is smaller than the 2.71 X2 from the Chi-Square Table. Therefore, according to the note at the top of the Table, we CANNOT reject the null hypothesis. No significant change has been observed.
Sign Test (test for differences when quantitative measurement is impossible)
As described above, the sign test is appropriate in cases where only ordinal or nominal data is available. The sign test tests for two different states (+ or -) in two related samples. The test makes few assumptions (only that the distribution is continuous and not normal).
The test allows a previous prediction of whether a "+" or "-" state will occur. As such, the sign test may also be used to measure the strength indicated, as well as the direction. The test is simply to count the number of times a predicted event occurs (+), and the number of times the predicted event does not occur (-). yes"> Tie cases are dropped.
Sign test example
A human resources manager suspects that his organization's performance appraisal system masks a problem in that, presently, both direct supervisors and their managers appraise employees' performance annually (e.g. one over one appraisals); the combined score achieved is averaged and applied to salary increases.
The appraisal system is on a 1-5 scale, with each increment meaning an effective 2% additional salary increase. The manager suspects that top supervisors' scores are skewed by favoritism and lack of personal knowledge. To test this, he selects 20 employees whose performance (from documented, quantified results from previous years) is clearly above average. These are rated as "1" and the direct supervisors' and their managers' scores shown below are the differences between this and their supervisors' ratings.
| Employee | Documented Employee Performance Score |
Direct Supervisor Score |
Difference Between Direct Supervisor Score and Documented Employee Score | Manager Score | Difference Between Manager Score and Documented Employee Score |
|---|---|---|---|---|---|
| 1 | 1 | 1 | 0 | 2 | 1 |
| 2 | 1 | 2 | 1 | 2 | 1 |
| 3 | 1 | 1 | 0 | 2 | 1 |
| 4 | 1 | 2 | 1 | 3 | 2 |
| 5 | 1 | 2 | 1 | 2 | 1 |
| 6 | 1 | 1 | 0 | 3 | 2 |
| 7 | 1 | 3 | 2 | 2 | 1 |
| 8 | 1 | 1 | 0 | 1 | 0 |
| 9 | 1 | 1 | 0 | 2 | 1 |
| 10 | 1 | 2 | 1 | 1 | 0 |
| 11 | 1 | 2 | 1 | 2 | 1 |
| 12 | 1 | 2 | 1 | 3 | 2 |
| 13 | 1 | 1 | 0 | 2 | 1 |
| 14 | 1 | 1 | 0 | 2 | 1 |
| 15 | 1 | 1 | 0 | 1 | 0 |
| 16 | 1 | 2 | 1 | 2 | 1 |
| 17 | 1 | 3 | 2 | 2 | 1 |
| 18 | 1 | 2 | 1 | 3 | 2 |
| 19 | 1 | 1 | 0 | 2 | 1 |
| 20 | 1 | 1 | 0 | 2 | 1 |
Does a statistical difference exist?
Sign test solution
The null hypothesis is that no difference exists between the measurements. That is, the direct supervisors and their managers have similar overall scores for all employees.
Because the data is ordinal, the measurements are expressed as differences from the prescribed "correct" measurements. Let the confidence level be a = 0.05 and use the Binomial Table shown in the Appendix. Predict direct supervisors difference is less than their managers, as follows:
|
Difference Between Direct Supervisor Score and Documented Employee Score Column 1 |
Difference Between Manager Score and Documented Employee Score Column 2 |
Direction Column 3 |
Sign Column 4 |
|---|---|---|---|
| 0 | 1 | < | + |
| 1 | 1 | = | 0 |
| 0 | 1 | < | + |
| 1 | 2 | < | + |
| 1 | 1 | = | 0 |
| 0 | 2 | < | + |
| 2 | 1 | > | - |
| 0 | 0 | = | 0 |
| 0 | 1 | < | + |
| 1 | 0 | > | - |
| 1 | 1 | = | 0 |
| 1 | 2 | < | + |
| 0 | 1 | < | + |
| 0 | 1 | < | + |
| 0 | 0 | = | 0 |
| 1 | 1 | = | 0 |
| 2 | 1 | > | - |
| 1 | 2 | < | + |
| 0 | 1 | < | + |
| 0 | 1 | < | + |
If the value in column 1 is:
- less than the value in column 2, a "<"sign is put in column 3
- higher than the value of column 2, a ">" is put in column 3
- equal to the value in column 2, then an "=" sign is put in column 3
If the direction in column 3 is:
- "<," then assign a "+" to column 4
- ">," then assign a "-" to column 4
- "=," then assign a 0 to column 4
Note: When a value of 0 is assigned to column 4, it indicates a tie and these observations are dropped from further analyses.
Since 6 cases ended in a tie, the sample size is reduced from 20 to 14 (20 - 6 = 14). Of these 14, 11 are in the + direction and 3 are in the - direction. Now we need to use the Binomial Table in the IBBCA Appendix to find the p-value.
Using the Binomial Table with N = 14 and x = 3, we find the occurrence of 0.029. We can then expect that direct supervisors and managers have similar overall scores for all employees only 2.9% of the time. Remember that with probabilities, if your confidence level is higher than the probability in the table, you should reject the null hypothesis. Since the 0.05 confidence level is higher than the probability in the table of 0.029, we can reject the null hypothesis and say that the human resources manager has proven his case.
Fisher Exact Probability Test
The fisher exact test is a non-parametric test similar to the Z test and the more widely used student's t test. It is dissimilar in that it requires none of the stringent parametric assumptions such as normally distributed data, equal variances or interval data. It does require independence.
It is a particularly appropriate test for small amounts of data when testing for adverse impact on test or job factor designs. But remember, the samples may be small but require independence.
The equation for calculating p is:
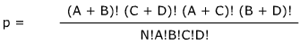
N is the standard sample size. These symbols designate a matrix in the form of:
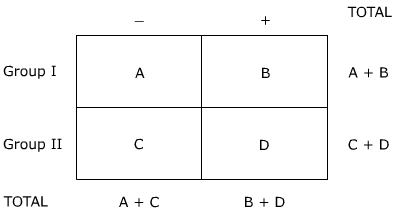
Fisher exact probability test example
With limited data, a human resources manager is concerned that a test question might show adverse impact on a minority group in testing for a rarely filled position. The unprotected group has passed the test question 5/6 times, while the minority group has managed 1/5 times. Since the question weights heavily in the final scores where overall differentiations are small, it has an overpowering effect; hence the concern. What might one say statistically about these rates of passing and failure?
Fisher exact probability test solution
The null hypothesis would be that the pass and fail outcomes should be in equal proportions, and chance should explain all differences.
The test is a study of the differences between two independent samples. Let us assume a confidence level of 95%; a = 0.05, N = 11.
Create the matrix:
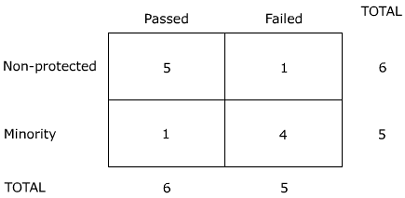
p = 6!5!6!5
11!5!1!1!4!
p = 720 x 120 x 720 x 120
39916800 x 120 x 1 x 1 x 24
p = 0.065
Since the calculated probability (p) is greater than 0.05, one could not reject the null hypothesis. Adverse impact has not been shown at this level. (To fully compute (p), one should repeat the calculation for B + C = 0; and these small probabilities should be cumulated.)
Note: One must be careful that others may utilize a different confidence level (e.g., a = 0.10) and reach the opposite conclusion. Also, for larger sample sizes (sample size greater than 20), use the chi-square, Kolmogorov-Smirnov or median test.
Chi-Square Test (Two Independent Samples)
The chi-square (X2) test of two independent samples is a counterpart to the fisher exact test, but it can be more easily applied to larger samples. It works well with both ordinal and nominal data, but the samples must be independent. It is particularly appropriate in human resources for data that can be divided into categories and on which frequency measurements can be made. As such, test question validation is a particularly fine example.
Frequencies are counted and the hypothesis is then tested with the equation. Frequencies are the number of cases which two groups of data fall into in selected categories.
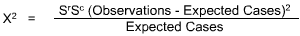
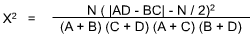
Chi-square test example
A new human resources officer finds that an organization's method of identifying "potential performance" might be causing as many problems as it solves. In reviewing those who had been rated "1," or being of high potential and ready for advancement, she notes that many had left the organization. It was her guess that once identified, such individuals became dissatisfied if advancement was not immediately forthcoming. To test this hypothesis, the potential performance results for 2016 are examined and the following results found:
Of those rated "1,"
Six left the organization in 2015 and 40 remained. Of those who did not advance in 2015, 12 left and 12 stayed. What does this result show statistically?
Chi-square test solution
The null hypothesis would be that no difference exists between the two populations.
The chi-square (X2) test is appropriate because the measurements are independent and nominal and are easily arranged in discrete categories. Let us assume a confidence level of 95% (a = 0.05). N is the number of cases (70). A matrix would be:
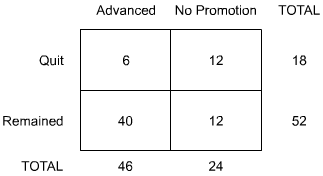
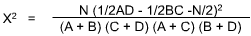
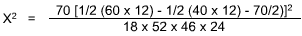
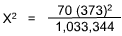
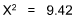
This number, when applied to the Chi-Square Table, shows a probability much lower than 0.05; indeed, even if only one direction is predicted (and here one could guess that those without advancement would leave), if a = 0.025 confidence level were used, the null hypothesis would still have to be rejected. Lack of advancement appears to be clearly related to turnover.
Median Test
In human resource administration, data will often be unevenly distributed (such as in clerical salaries) so that the skewed distribution will lead to highly variable means, even though medians might be similar. This problem becomes more acute when measurements are ordinal rather than interval. This can be handled with the median test, which allows you to test whether two samples have been drawn from populations with the same median.
Median test example
A personnel manager decides that median data does a better job of explaining performance appraisal and salary levels for clerical employees than averages. He is asked to test whether or not the present merit salary increase program is effective. Do better performers receive more than poorer performers?
| Employee | Appraisal Level (1 - 10 Scale) | Salary ($)* |
|---|---|---|
| A | 7 | 26,000 |
| B | 2 | 30,000 |
| C | 9 | 29,000 |
| D | 6 | 29,000 |
| E | 9 | 26,000 |
| F | 1 | 34,000 |
| G | 9 | 27,000 |
| H | 10 | 36,000 |
| I | 1 | 27,000 |
| J | 10 | 28,000 |
| K | 9 | 35,000 |
| L | 8 | 27,000 |
| M | 9 | 33,000 |
| N | 6 | 30,000 |
| O | 9 | 27,000 |
| P | 7 | 29,000 |
| Q | 1 | 29,000 |
| R | 7 | 27,000 |
| S | 10 | 28,000 |
| T | 8 | 26,000 |
| U | 6 | 27,000 |
| V | 6 | 35,000 |
| W | 3 | 26,000 |
| X | 9 | 26,000 |
| Y | 10 | 30,000 |
| Z | 10 | 27,000 |
Step 1. Find the medians
The median is the middle value of a list of numbers. To find the median:
- Sort the data in ascending or descending order.
- Find the middle value of the list, where 50% of the data are less than or equal to the median, and 50% of the data are greater than or equal to the median.
Re-arrange the table above into two separate tables: one for appraisal level and one for salaries.
| Appraisal Level (1 - 10 Scale) | Salary ($) | |
|---|---|---|
| 1 | 26,000 | |
| 1 | 26,000 | |
| 1 | 26,000 | |
| 2 | 26,000 | |
| 3 | 26,000 | |
| 6 | 27,000 | |
| 6 | 27,000 | |
| 6 | 27,000 | |
| 6 | 27,000 | |
| 7 | 27,000 | |
| 7 | 27,000 | |
| 7 | 27,000 | |
| 8 | 28,000 | |
| 8 | 28,000 | |
| 9 | 29,000 | |
| 9 | 29,000 | |
| 9 | 29,000 | |
| 9 | 29,000 | |
| 9 | 30,000 | |
| 9 | 30,000 | |
| 9 | 30,000 | |
| 10 | 33,000 | |
| 10 | 34,000 | |
| 10 | 35,000 | |
| 10 | 35,000 | |
| 10 | 36,000 |
You find median values of 8 for appraisal level and $28,000 for salary.
Note: If there is an even number of observations, as in the list above, average the middle 2 values to find the median. In this case, (8 + 8) / 2 = 8 and ($28,000 + $28,000) / 2 = $28,000.
Step 2. Set up the matrixes
After finding the medians, we must now determine if any deviations from these medians are statistically significant. To do that, we will use the chi-square test.
In order to set up the matrix for observed values, you must first rearrange the original table to reflect above or below median appraisal level and salary.
| Employee | Appraisal Level (1 - 10 Scale) |
Compared to Median |
Salary ($)* | Compared to Median |
|---|---|---|---|---|
| A | 7 | BELOW | 26,000 | BELOW |
| B | 2 | BELOW | 30,000 | ABOVE |
| C | 9 | ABOVE | 29,000 | ABOVE |
| D | 6 | BELOW | 29,000 | ABOVE |
| E | 9 | ABOVE | 26,000 | BELOW |
| F | 1 | BELOW | 34,000 | ABOVE |
| G | 9 | ABOVE | 27,000 | BELOW |
| H | 10 | ABOVE | 36,000 | ABOVE |
| I | 1 | BELOW | 27,000 | BELOW |
| J | 10 | ABOVE | 28,000 | ---------- |
| K | 9 | ABOVE | 35,000 | ABOVE |
| L | 8 | ---------- | 27,000 | BELOW |
| M | 9 | ABOVE | 33,000 | ABOVE |
| N | 6 | BELOW | 30,000 | ABOVE |
| O | 9 | ABOVE | 27,000 | BELOW |
| P | 7 | BELOW | 29,000 | ABOVE |
| Q | 1 | BELOW | 29,000 | ABOVE |
| R | 7 | BELOW | 27,000 | BELOW |
| S | 10 | ABOVE | 28,000 | ---------- |
| T | 8 | --------- | 26,000 | BELOW |
| U | 6 | BELOW | 27,000 | BELOW |
| V | 6 | BELOW | 35,000 | ABOVE |
| W | 3 | BELOW | 26,000 | BELOW |
| X | 9 | ABOVE | 26,000 | BELOW |
| Y | 10 | ABOVE | 30,000 | ABOVE |
| Z | 10 | ABOVE | 27,000 | BELOW |
Now you can set up a matrix for observed values.
| Salary | |||
|---|---|---|---|
| Appraisal Level | Above | Below | Total |
| Above | 5 | 5 | 10 |
| Below | 7 | 5 | 12 |
| TOTAL | 12 | 10 | 22 |
From the table above, there are:
- 5 employees who have above median appraisal level and salary
- 7 employees who have below median appraisal level and above median salary
- 5 employees who have above median appraisal level and below median salary
- 5 employees who have below median appraisal level and salary
Because the sample size is greater than 20 and no frequency is less than 5, we can proceed with the chi-square test.
Now set up the matrix for expected values.
Recall from the previous section on the chi-square test that you must first convert the matrix for observed values into fractions of 100 if the total observation is less than 100, as it is in this case. Below is an adjusted matrix for observed values:
| Salary | |||
|---|---|---|---|
| Appraisal Level | Above | Below | Total |
| Above | 22.73 |
22.73 |
45.46 |
| Below | 31.82 |
22.73 |
54.55 |
| TOTAL | 54.55 |
45.46 |
100 |
Now, we can set up the matrix for expected values:
| Salary | ||||
|---|---|---|---|---|
| Above | Below | |||
| 0.5455 | 0.4546 | |||
| Appraisal Level | Above | 0.4546 | 24.80 | 20.67 |
| Below | 0.5455 | 29.76 | 24.80 | |
Step 3. Perform the chi-square test
Solve for X2.
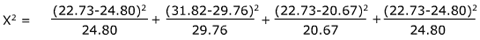
Interpretation
X2 equals 0.69, and the degree of freedom is 1. Remember, the degree of freedom equals the number of columns minus 1, times the number of rows minus 1.
(2-1) x (2-1) = 1
So take this data to the Chi-Square Table in the IBBCA Appendix. Going to the df column of 1 and the confidence level of 95% ( or 0.05 p-value), you find a result of 3.84. As the note at the top of the Chi-Square Table tells you, since your X2 is much smaller than 3.84, you CANNOT reject the null hypothesis. Hence, you must conclude that no difference exists between the populations; poorer and better performers are being paid similarly. This implies that this organization's merit plan needs to be reviewed.
Mann Whitney U Test
Assuming that ordinal measurement is present and the sample size is above 20 (although the latter requirement is not absolutely necessary), the Mann Whitney U Test is the most effective way of testing two independent groups. (This assumes the t test is not used because the analyst does not wish to accept parametric assumptions. Also, when faced with samples smaller than 20, tables are available.)
The test is similar to all other statistical tests. One inspects two groups for difference. With the Mann Whitney U Test, however, the data is ranked in terms of 1 - N and n1, the number of cases in the smaller group is identified (n2 is the larger). R1 is the sum of the ranks of those observations in the small group, n1.
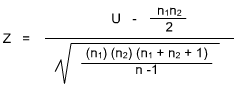
where
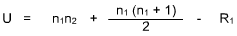
Mann Whitney U test example
The human resource manager who utilized the median test wishes to find a more powerful test and was satisfied that the skews in distribution were uniform among the groups. Since the measurements constitute an ordinal scale, what can be concluded by utilizing the Mann Whitney U Test?
Mann Whitney U test solution
The null hypothesis would be that no difference exists between the groups of better and poorer performers. Again, disproving this would allow you to conclude that a difference does exist. Again, let N = 26 and a = 0.01. (We take the approach of dividing ties between the groups.)
| Poorer Performers | Salary ($)* | Rank |
|---|---|---|
| V | 35,000 | 24.5 |
| F | 34,000 | 23.0 |
| N | 30,000 | 20.0 |
| B | 30,000 | 20.0 |
| D | 29,000 | 16.5 |
| P | 29,000 | 16.5 |
| Q | 29,000 | 16.5 |
| I | 27,000 | 9.0 |
| R | 27,000 | 9.0 |
| U | 27,000 | 9.0 |
| T | 26,000 | 3.0 |
| A | 26,000 | 3.0 |
| W | 26,000 | 3.0 |
R1 = 173
| Poorer Performers | Salary ($)* | Rank |
|---|---|---|
| H | 36,000 | 26.0 |
| K | 35,000 | 24.5 |
| M | 33,000 | 22.0 |
| Y | 30,000 | 20.0 |
| C | 29,000 | 16.5 |
| S | 28,000 | 13.5 |
| J | 28,000 | 13.5 |
| Z | 27,000 | 9.0 |
| O | 27,000 | 9.0 |
| G | 27,000 | 9.0 |
| L | 27,000 | 9.0 |
| E | 26,000 | 3.0 |
| X | 26,000 | 3.0 |
R2 = 178
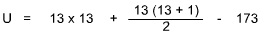
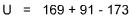
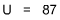
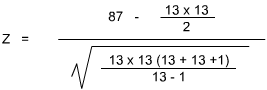
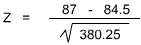
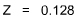
Using the Normal Distribution Table, we find p = 0.4491 for a one-direction test. With 0.01 as our goal, we can hardly talk about rejecting the null hypothesis.
Wald-Wolfowitz Runs Test
The Wald-Wolfowitz Runs test is a non-parametric test used to test a hypothesis that 2 dependent samples differ in some manner. The differences do not have to be specified. (If a difference is found with this test, other tests should be used to identify the source.) In discrimination testing, it can be used to test for biases between 2 samples.
To use the Wald-Wolfowitz Runs test, we need to calculate a z-score according to the following formula.
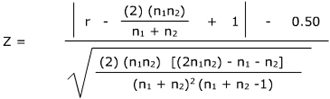
| r | the number of runs present when the data uses ordinal ranking |
|---|---|
| n1 | smaller sample count in the 2 test groups |
| n2 | larger sample count in the 2 test groups |
The z-score is then compared to the z-table, and a p-value is obtained to determine significance.
Wald-Wolfowitz runs test example
A personnel manager is greatly concerned that a particular section of questions in an entrance exam has an adverse impact on minority groups. In inspecting the scores for protected and non-protected classes, she finds:
| SECTION TEST SCORES | |
|---|---|
| Protected Group | Non-protected Group |
46 |
64 |
58 |
93 |
21 |
57 |
16 |
78 |
57 |
72 |
9 |
102 |
22 |
39 |
63 |
86 |
5 |
69 |
32 |
73 |
40 |
|
91 |
|
What conclusions might be tested for and drawn from this data? Assume a confidence level of 90%.
Wald-Wolfowitz runs test solution
Setting up the runs. In order to use the Wald-Wolfowitz formula above, we must find r, n1 and n2. We will proceed with finding r first.
To calculate r, we place the scores in rank order:

Remember, always use the least number of runs possible.
Finding n1 and n2. Recall that n1 is the smaller sample count and n2 is the larger sample count in the 2 test groups, respectively. The protected group has a smaller sample size of 10, while the non-protected group has a sample size of 12. Therefore, n1 = 10 and n2 = 12.
Solving for Z

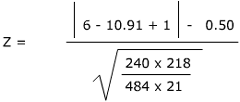
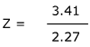

Using the Z Table, go to 1.5 in the left-hand column. To find the rest of the fraction, move across the table to 0.00 in the top hand row. You find a z-score of 0.0668. This is smaller than our assumed p-value (confidence level) of 0.10. Therefore, according to the note at the top of the Z Table, we reject the null hypothesis. The 2 groups differ in some way, and if the test section scores are used for decision making, they could adversely affect the minority group in a statistically significant manner.
Internet Based Benefits & Compensation Administration
Thomas J. Atchison
David W. Belcher
David J. Thomsen
ERI Economic Research Institute
Copyright © 2000 -
Library of Congress Cataloging-in-Publication Data
HF5549.5.C67B45 1987 658.3'2 86-25494 ISBN 0-13-154790-9
Previously published under the title of Wage and Salary Administration.
The framework for this text was originally copyrighted in 1987, 1974, 1962, and 1955 by Prentice-Hall, Inc. All rights were acquired by ERI in 2000 via reverted rights from the Belcher Scholarship Foundation and Thomas Atchison.
All rights reserved. No part of this text may be reproduced for sale, in any form or by any means, without permission in writing from ERI Economic Research Institute. Students may download and print chapters, graphs, and case studies from this text via an Internet browser for their personal use.
Printed in the United States of America
10 9 8 7 6 5 4 3 2 1
ISBN 0-13-154790-9 01





The ERI Distance Learning Center is registered with the National Association of State Boards of Accountancy (NASBA) as a sponsor of continuing professional education on the National Registry of CPE Sponsors. State boards of accountancy have final authority on the acceptance of individual courses for CPE credit. Complaints regarding registered sponsors may be submitted to the National Registry of CPE Sponsors through its website: www.learningmarket.org.